# 2022.02
# 2/28 자바스크립트 동작 원리
자바스크립트의 실행은 자바스크립트 엔진에 의해서 이뤄진다.
자바스크립트 엔진은 자바스크립트 코드를 파싱해서 CPU가 이해할 수 있는 저수준 언어로 변환하고 실행하는 역할을 한다. 자바스크립트 엔진은 자바스크립트를 해석해서 AST를 생성한다. 그리고 AST를 기반으로 인터프리터가 실행할 수 있는 중간 코드인 바이트코드를 생성하여 실행한다.
자바스크립트 엔진은 메모리 힙과 콜 스택으로 이뤄져있다. 메모리 힙에는 선언한 변수, 함수에 대한 메모리 할당이 이뤄지는 곳이고, 콜 스택에는 실행 컨텍스트가 쌓이면서 코드가 실행이 된다. 자바스크립트는 싱글스레드 프로그래밍 언어이기 때문에 콜 스택이 하나밖에 없는데, 그런 이유로 로드가 너무 큰 작업이 블로킹하지 않도록 비동기 코드를 사용할 수 있다.
콜 스택에 비동기 로직이 쌓이면 web APIs를 호출하고, Web API는 비동기 로직 안에 담긴 콜백을 태스크큐에 순차적으로 넣는다. 이때 이벤트 루프가 반복적으로 콜 스택이 비어있는지를 틱(tick)하면서 확인하고, 콜 스택이 유휴 상태가 되면 태스크큐에 있는 함수들을 스케줄링해서 콜 스택에 쌓는다.
ES6부터는 Promise가 도입되었는데, 프로미스는 태스크큐에 쌓이지 않고 마이크로태스크큐에 쌓인다. 그리고 마이크로태스크큐에 있는 콜백은 태스크큐 보다 우선하기 때문에 콜스택이 비게 되면 이벤트루프는 마이크로태스크큐에 있는 콜백을 먼저 스케줄링하고, 마이크로태스크큐 또한 비게 되었을 때 태스크큐에 있는 콜백을 스케줄링한다.
# 2/27 쿠키, 로컬스토리지, 세션스토리지 비교
HTTP는 상태가 없다. stateless하다고 표현하는데, HTTP는 전형적인 비동기 프로토콜이기 때문에 데이터를 요청하고 응답을 받으면 연결을 끊는다. (전화 vs 워키토키: 전화는 동기 프로토콜, 워키토키는 비동기 프로토콜에 비유)
따라서 유저의 상태와 같은 상태를 저장할 필요가 있는 정보들을 유지하기 위해 웹 스토리지가 만들어졌다.
# 쿠키
- 브라우저에 저장되는 작은 크기의 문자열 (최대 4KB)
- 만료 기간을 정하지 않은 쿠키를 세션 쿠키, 만료 기간이 있는 쿠키는 영구 쿠키
- 같은 도메인에서 만들어진 쿠키 전송
- 단점: CSRF, XSS에 노출, HTTP 요청 시 자동으로 모든 쿠키 전송
# 웹 스토리지
- 쿠키보다 더 많은 5MB의 저장 용량
- 요청 시 헤더에 전송하지 않음. 쿠키의 CSRF, 트래픽 문제 해결
- 직렬화를 통해 객체 저장 가능.
- 로컬 스토리지는 도메인과 브라우저 별로 독립된 스토리지를 사용하고, 세션 스토리지는 도메인, 브라우저, 탭 별로 독립된 스토리지 사용.
- 세션 스토리지는 탭이 종료될 때 삭제되고, 로컬스토리지는 직접 삭제해야 함.
- 브라우저 버전에 따라 웹 스토리지를 지원하지 않을 수 있음: 사파리 시크릿 모드
- 단점: 웹 스토리지도 쿠키와 마찬가지로 XSS에 취약. 스토리지가 독립적이기 때문에 브라우저와 탭 간 공유 불가. 만료 기간 설정 불가. 동기적으로 실행되기 때문에 메인 스레드를 블로킹할 수 있음.
# 정리
- 쿠키와 웹 스토리지는 보안 문제가 있기 때문에 민감한 정보는 저장하지 않는다.
- 쿠키는 기간을 설정하거나 자동으로 서버로 전송되어야 하는 작은 용량의 데이터인 경우에 사용. (n일 동안 보지 않기, 비로그인 장바구니)
- 세션 스토리지는 탭이 종료될 때 삭제되도 괜찮은 데이터 보관. (이전 페이지 저장, 이전 스크롤 위치 저장)
- 로컬 스토리지는 브라우저 종료 시에도 유지되어야 하는 데이터 보관. (사용자 설정 저장, 글 임시 저장)
# 단점 보완
- XSS:
- HttpOnly 옵션을 사용해서 자바스크립트로 접근이 불가능하도록 함
- 사용자 입력이 자바스크립트 코드로 실행될 수 있는 innerHTML, eval, document.write와 같은 코드를 사용하지 않는다.
- CSRF:
- SameSite(strict, lax)를 사용해서 같은 도메인의 요청에만 쿠키를 전송. (크롬의 default는 lax)
- Referer 검증을 통해 요청 온 사이트의 도메인을 확인.
# 2/26 Hydration & Isomorphic JavaScript
Hydration은 React.js, Vue.js 등의 Client-side Framework가 서버에서 전송한 정적 문서를 데이터 변경에 반응할 수 있는 동적 형태로 변환하는 클라이언트 측 프로세스 Isomorphic JavaScript은 SSR 과정 중 한 JavaScript 코드가 Node.js와 Browser 환경 모두에서 동작하게 되는데, 이렇게 두 환경에서 동작할 수 있는 JavaScript코드를 뜻한다.
# 2/25 바벨 Babel.js
Babel.js는 자바스크립트 ES6+/ES.NEXT의 문법을 사용할 수 있게 해주는 트랜스파일러다.
ES6 이후의 문법은 모든 브라우저 환경에서 지원되는 문법이 아니기 때문에 다양한 브라우저 환경에서 안전하게 코드를 실행하기 위해서는 바벨과 같은 트랜스파일러를 활용해 ES5 문법으로 변환해야 한다.
# 트랜스파일러 vs 컴파일러
- 컴파일: 한 언어로 작성된 소스코드를 다른 언어로 변환하는 것. 고수준의 프로그래밍 언어로 작성된 코드를 object code, bytecode, machine code와 같은 저수준의 언어로 변환하는 도구. eg. java -> bytecode / c -> assembly
- 트랜스파일: 한 언어로 작성된 소스 코드를 비슷한 수준의 추상화를 가진 다른 언어로 변환. source-to-source compiler 혹은 transcompiler라고도 불리워지고, 고수준의 언어들 사이에서 소스코드를 변환하는 도구이며 결과 코드는 여전히 인간이 읽을 수 있다. eg. es6 -> es5 / c++ -> c / coffescript -> javascript 트랜스파일러는 컴파일러의 일종이다.
Babel.js 공식문서 (opens new window)
# 2/24 인터페이스와 타입 차이
Almost all features of an interface are available in type, the key distinction is that a type cannot be re-opened to add new properties vs an interface which is always extendable.
# 차이점
type TGender = 'female' | 'male';
interface IUser {
// name에 할당된 string 값을 readonly만 하도록
readonly name: string;
readonly gender: TGender;
}
// 인터페이스의 경우 동일한 이름으로 여러 번 선언해도 컴파일 시점에 결합이 됨
// 선언 병합 (Declaration Merging)
interface IUser {
readonly country: string;
}
interface IUserInfo extends IUser {
profile: string;
age: number;
sns?: string;
}
// 타입은 인터페이스와 결합할 수 있음 (그 반대도 가능)
type TUserInfo = IUser & {
profile: string;
age: number;
sns?: string;
};
// 여러개 타입과 인터페이스 동시 상속 가능
interface IStyle extends TColor, IDisplay, TGeometry {
tagName: string;
}
type TStyle = TColor & IDisplay & TGeometry {
tagName: string;
}
type TObj = {
[prop: string]: string;
}
interface IObj {
[prop: string]: string;
}
// 함수 타입
interface IGetApi {
(url: string, search?: string): Promise<string>;
}
// 함수 표현식에만 사용 가능
type TGetApi = {
(url: string, search?: string): Promise<string>;
}
type TFooFunction = () => string; // 이것도 가능
// 클래스인 경우에 인스턴스를 만들기 위해서 생성자가 호출이 되는데,
// 클래스의 규격과 생성자가 만들어내는 인스턴스의 규격이 다를 수 있음. 아래와 같이 표기
interface IRectConstructor {
new (s: number, y: number, width: number, height: number): IRect;
}
class Rect implements allTypes.IRect {
id : number;
x: number;
y: number;
width: number;
height: number;
constructor(x: number, y: number, width: number, height: number){
this.id = Math.random() * 100000;
this.x = x;
this.y = y;
this.width = width;
this.height = height;
}
}
function createDefaultRect(cstor: allTypes.IRectConstruct){
return new cstor(0, 0, 100, 100);
}
const rect1 = new Rect(0, 0, 100, 20);
const rect2 = createDefaultRect(Rect);
- 표현 방법에서의 차이점:
=을 쓰냐 안 쓰냐 - 타입을 결합하고 조합하는 방식에서의 차이점: interface는
extends, type은&type과 interface 교차 결합 가능. - 유니온 타입
|은 인터페이스로는 지원이 되지 않는다. - 타입은 존재하는 primitives에 custom name을 붙일 수 있지만 인터페이스는 primitive type을 리네이밍할 수 없다.
- 타입 알리아스는 중복 선언이 불가능하지만, 인터페이스는 중복 선언이 가능하다. 중복선언 되었을 때에는 그 둘을 결합한 인터페이스가 된다.(자동 확장)
- 인터페이스는 항상 public 공개된 속성만 기술할 수 있음 (클래스 내에서 private 설정 불가)
- 데이터를 표현할 때는 타입 알리아스를 쓰고, 메서드와 같은 구체적인 행위까지 포함된 객체를 표현할 때는 인터페이스. 클래스의 경우 클래스 자체가 데이터와 행위를 포괄하고 있기 때문에 인터페이스를 쓰는 것이 자연스럽다.
# 성능 비교
- 타입을 결합하는 경우에 결합의 결과가
never가 나올 수 있는 문제가 있음. cf.never: 항상 오류를 출력하거나 리턴 값을 절대로 내보내지 않음을 의미여러 type 혹은 interface를 &하거나 extends할 때를 생각해보자. interface는 속성간 충돌을 해결하기 위해 단순한 객체 타입을 만든다. 왜냐하면 interface는 객체의 타입을 만들기 위한 것이고, 어차피 객체 만 오기 때문에 단순히 합치기만 하면 되기 때문이다. 그러나 타입의 경우, 재귀적으로 순회하면서 속성을 머지하는데, 이 경우에 일부 never가 나오면서 제대로 머지가 안될 수 있다. interface와는 다르게, type은 원시 타입이 올수도 있으므로, 충돌이 나서 제대로 머지가 안되는 경우에는 never가 떨어진다. 아래 예제를 살펴보자. 출처 (opens new window)
type type2 = { a: 1 } & { b: 2 }; // 잘 머지됨
type type3 = { a: 1; b: 2 } & { b: 3 }; // resolved to `never`
const t2: type2 = { a: 1, b: 2 }; // good
const t3: type3 = { a: 1, b: 3 }; // Type 'number' is not assignable to type 'never'.(2322)
const t3: type3 = { a: 1, b: 2 }; // Type 'number' is not assignable to type 'never'.(2322)
- interface 합성의 경우 캐시가 되지만 타입은 그렇지 않다.
- 타입 합성 시 합성 자체에 대한 유효성 판단 이전에 모든 구성요소에 대해 타입 검증하므로 컴파일 시에 상대적으로 성능이 좋지 않다.
# typeScript 팀의 의도
OCP 원칙에 따라 확장에 열려있는 JavaScript 객체의 동작 방식과 비슷하게 연결하도록 interface를 설계함. 따라서 가능한 type alias 보단 interface를 사용하고, 유니온 타입 혹은 튜플 타입을 반드시 써야 하는 상황이면 type alias를 사용하도록 권장한다.
TypeScript 공식문서에서 type과 interface를 비교한 글 (opens new window)
# 2/23 any와 unknown 차이
사용하는 데이터의 구조를 파악하기 힘들 때 any, unknown을 사용하게 되는데... 사실 상 unknown을 사용하는 것이 바람직하다. 그 이유는 any는 기본적으로 모든 타입 체크를 무력화 시키기 때문. 모든 타입 검증을 무력화하기 때문에 any로 오는 것은 어떤 종류의 타입 검증보다도 우선한다.
# any의 효용과 단점
any는 타입 디자인을 감추기 때문에 any로 가득한 타입스크립트는 자바스크립트보다 못하다. 그럼에도 불구하고 any가 주는 효용은,
- 기존 자바스크립트로 구현되어 있는 코드에 타입스크립트를 점진적으로 적용해나갈 때 사용 가능하다
- 모든 타입 체크를 무력화 시키기 때문에 개발 생산성은 높아질 수 있다.
- 타입 검증을 무력화하기 때문에 오남용하게 될 경우 typeScript의 디자인 목표에 반하는 것이며 프로그램의 안정성을 낮추게 된다.
그럼 타입스크립트는 왜 이런 모순적인 타입을 가지고 있는 걸까요? 그 이유는 타입스크립트의 디자인 목표에서부터 추측할 수 있습니다.
타입스크립트의 개발 목표는 철옹성과 같은 안전한 타입 시스템을 도입해 자바스크립트에서 발생할 수 있는 모든 오류를 걷어내는 데 있는 게 아니라, 자바스크립트의 생산성을 보전하면서 오류가 될 수 있는 코드들을 걸러주는 거름망 같은 타입 시스템을 도입하는 데 있기 때문에 any와 같이 안전성을 해치지만 생산성을 보전하는 데에 도움이 되는 타입을 만들었다고 생각합니다.
그렇기에 any의 가치는 자바스크립트 코드를 그대로 사용할 수 있게 함으로서 타입스크립트의 생산성을 높여주는 데 있다고 할 수 있겠습니다. - 출처 (opens new window)
# any가 아닌 unknown을 써야 하는 이유
- unknown의 경우 any와 unknown 타입을 제외한 타입의 변수에 할당이 불가능하다.
let notSure: unknown;
notSure = 1;
notSure = 'maybe a string instead''
let anyType: any;
anyType = notSure; // any에는 unknown 할당 가능
let numberType: number;
numberType = notSure; // compile error: Type 'unknown' is not assignable to type 'number'
- unknown 타입과 다른 타입을
|유니온 타입으로 합성하게 되면 unknown 타입이 반환된다. 그리고 다른 타입과 unknown을&로 교집합 처리하면 처리된 다른 타입이 반환된다.
type unknownType = unknown | string // unknown
type stringType = unknown & string // string
- unknown 타입의 변수는 프로퍼티에 접근할 수 없고, 메서드를 호출할 수 없으며, 인스턴스를 생성할 수도 없다.
따라서 unknown 타입의 변수를 사용할 때에는 타입 가드를 사용해야 한다.
### 타입 가드 예시
#### 예시 1
```ts
let variable: unknown
declare function isFunction(x: unknown): x is Function
if (isFunction(variable)) {
variable() // OK
}
# 예시 2
let foo: unknown = 10;
function hasXYZ(obj: any): obj is { x: any; y: any; z: any } {
return (
!!obj && typeof obj === 'object' && 'x' in obj && 'y' in obj && 'z' in obj
);
}
// Using a user-defined type guard...
if (hasXYZ(foo)) {
// ...we're allowed to access certain properties again.
foo.x.prop;
foo.y.prop;
foo.z.prop;
}
// We can also just convince TypeScript we know what we're doing
// by using a type assertion.
upperCase(foo as string);
function upperCase(x: string) {
return x.toUpperCase();
}
// microsoft dev blogs, RC announcement
# 예시 3
function isArrayOfProducts(obj: unknown): obj is Product[] {
return Array.isArray(obj) && obj.every(isProduct);
}
function isProduct(obj: unknown): obj is Product {
return obj != null && typeof (obj as Product).id === 'string';
}
async function loadProducts(): Promise<Product[]> {
const response = await fetch('https://api.mysite.com/products');
const products: unknown = await response.json();
if (!isArrayOfProducts(products)) {
throw new TypeError('Received malformed products API response');
}
return products;
}
참고로 타입 가드 대신 assertion을 사용해서 에러를 해결할 수도 있지만.. 타입 단언으로 해결해버리는 순간 미리 에러를 잡아내지 못하고 런타임에서 앱이 죽어버릴 수도 있다는 것을 명심..
# 참고
TypeScript 3 버전에서 추가된 unknown의 풀리퀘 (opens new window) 안전한 any 타입 만들기 (opens new window)
# 2/22 JavaScript의 변천사
JavaScript는 1995년에 처음 개발되었다. 파이어폭스의 전신이었던 넷스케이프에 LiveScript라는 이름으로 처음 탑재가되었다. 이 당시에는 HTML을 간단하게 조작하기 위한 목적으로 만들어진 언어라서 갖고 있던 스펙도 많지 않았다. 그리고 이후에 웹이 발전하게 되면서 마이크로소프트의 IE에서 LiveScript를 사용하기 시작한다.
이후에 1997년에 ECMA라는 표준 단체에서 JavaScript, ECMAScript라는 이름으로 표준화를 진행한다. 2000년대 닷컴버블 시대를 맞이하면서 자바스크립트는 꾸준히 새로운 버전이 릴리즈되는데, 2009년에 나온 버전이 ECMAScript 5.0 버전이다. 그리고 이 버전 5가 지금까지도 주도적인 버전으로 사용되고 있다.
2015년부터는 ECMAScript2015로 불리우며 연도로 버저닝을 하고 있는데, 모던 자바스크립트라고 일컫는 버전이 ES2015 부터고 현재 우리가 사용하는 문법이다. 그럼에도 ECMAScript 5.0이 주도적인 버전인 이유는 다양한 브라우저와 브라우저의 버전이 지원하기 때문이다. 따라서 ES2017과 같은 문법을 사용하기 위해서는 변환기가 필요한데, 트랜스파일러라고 이야기 한다. (타입스크립트도 일종의 트랜스파일러) 최신 자바스크립트 문법을 사용해서 작성을 하게 되면 트랜스파일러를 통해 ES5 버전으로 변환을 해서 웹브라우저에서 동작시킨다.
# 2/21 HTMLCollection vs NodeList
| HTMLCollection | NodeList |
| getElementsByTagName, getElementsByClassName | querySelectorAll |
| Live 객체 (노드 객체 상태를 실시간으로 반영하기 때문에 DOM이 변경될 때 반영됨) | 대부분 Non-live 객체 (과거 정적인 상태를 유지) |
| forEach 사용 불가 | forEach 사용 가능 |
| DOM Api가 여러 개의 결과값을 반환하기 위한 DOM 컬렉션 객체 | |
| 유사 배열 객체이면서 이터러블 (map, filter, reduce와 같은 메서드 사용 불가) | |
| 배열로 변환 후 사용 권장 | |
- 유사배열객체: length를 가지고 있어서 인덱싱을 할 수 있고, for 문 사용 가능
- 이터러블: for of 반복문을 사용할 수 있고 스프레드 연산자를 사용할 수 있으며 배열 디스트럭처링을 할 수 있음
# 2/20 리팩터링: 기능 이동
프로그램 요소를 생성 혹은 제거하거나 이름을 변경하는 리팩터링도 있지만, 요소를 다른 컨텍스트(클래스나 모듈 등)로 옮기는 일 역시 리팩터링의 중요한 축이다.
가령 반복문에서 자주 사용하는 리팩터링은 두 가지다. 첫 번째는 각각의 반복문이 단 하나의 일만 수행하도록 하는 반복문 쪼개기가 있고, 두 번째는 반복문을 완전히 없애버리는 반복문을 파이프라인으로 바꾸기가 있다.
# 함수 옮기기
좋은 소프트웨어 설계의 핵심은 모듈화가 얼마나 잘 되어 있느냐를 뜻하는 모듈성이다. 모듈성이란 프로그램의 어딘가를 수정하려 할 때 해당 기능과 깊이 관련된 작은 일부만 이해해도 가능하게 해준다. 보통은 이해도가 높아질수록 소프트웨어 요소들을 더 잘 묶는 새로운 방법을 깨우치게 된다.
모든 함수는 어떤 컨텍스트 안에 존재한다. 전역 함수도 있지마ㅑ 대부분은 특정 모듈에 속한다. 객체 지향 프로그래밍의 핵심 모듈화 컨텍스트는 클래스다.
선택한 함수가 현재 컨텍스트에서 사용 중인 모든 요소를 살펴보고 같이 옮겨야 할 것이 있는지 고민한다. 선택한 함수가 다형 메서드인지 확인한 후, 선택한 함수를 타깃 컨텍스트로 복사한다. 기존의 컨텍스트(소스 함수)를 타깃 함수의 위임 함수가 되도록 수정한다.
# 필드 옮기기
프로그램의 상당 부분이 동작을 구현하는 코드로 이뤄지지만 프로그램의 진짜 힘은 데이터 구조에서 나온다. 주어진 문제에 적합한 데이터 구조를 활용하면 동작 코드는 자연스럽게 단순하고 직관적으로 짜여진다. 경험적으로 도메인 주도 설계 같은 것들이 이 부분을 개선해주기는 하지만 초기 설계에서는 어렵다.
따라서 현재 데이터 구조가 적절치 않다는 것을 깨닫는 즉시 수정해야 한다. 가령 함수에 항상 함께 전달되는 데이터 조각들은 상호 관계가 명확하도록 한 레코드에 담는 것이 좋다. 이 데이터들이 쪼개져 있었다면 단 한 번만 갱신되도록 다른 위치로 옮겨야 한다.
# 문장을 함수로 옮기기
중복 제거는 코드를 건강하게 관리하는 효과적인 방법이다. 만약 특정 함수를 호출할 때마다 그 앞뒤로 똑같은 코드가 추가로 실행된다면 피호출 함수로 합치도록 한다. 따라서 그 부분에서 무언가 수정할 일이 생겼을 때 그곳만 수정하면 된다.
# 문장을 호출한 곳으로 옮기기
함수는 프로그래머가 쌓아 올리는 추상화의 기본 빌딩 블록이다. 하지만 추상화라는 것이 그 경계를 항상 올바르게 긋기가 쉽지 않다. 따라서 초기에는 응집도 높고 한 가지 일만 수행하던 함수가 어느새 둘 이상의 다른 일을 수행하게 바뀔 수 있다는 뜻이다.
가령 여러 곳에서 사용하던 기능이 일부 호출자에게는 다르게 동작하도록 해야 한다면, 달라진 동작을 함수에서 꺼내 해당 호출자로 옮겨야 한다. 우선 문장 슬라이드하기를 적용해 달라지는 동작을 함수의 시작 혹은 끝으로 옮긴 다음, 문장을 호출한 곳으로 옮기기 리팩터링을 적용하면 된다. 달라지는 동작을 호출자로 옮긴 뒤에는 필요할 때마다 독립적으로 수정할 수 있다.
# 2/19 리액트 상태 관리는 어떻게 하는 것이 좋을까
# Redux (client state) + React Query (server state)
나는 Redux로 전역 상태를 관리하고, 서버에서 가져오는 데이터는 React Query를 활용해 관리하고 있다.
리액트는 데이터가 단방향으로 흐르기 때문에 부모에서 상태가 변경되는 경우 자식들 또한 동시에 리렌더링 된다. 따라서 렌더링 최적화를 위해 너무 많은 컴포넌트를 지나가는 state에 경우에 리덕스를 활용해 전역 상태로 관리한다.
또한 리액트 쿼리를 사용해서 비동기 로직의 데이터를 따로 관리하고 있다. 리액트 쿼리를 사용하면서 useState 훅을 사용하지 않고도 최신의 상태를 유지하면서 렌더링을 줄일 수 있었다.
# why: 리액트 성능 최적화
위와 같이 관리하는 이유는 리액트 성능 최적화 때문이었다.
하나의 애플리케이션을 초기 설계부터 개발하고 런칭하여 유지 보수하는 단계를 순차적으로 경험한 적이 있다.
점점 기능이 고도화될수록 가장 어려움을 겪었던 부분은 너무 많은 상태에 의해 발생하는 예상치 못한 버그와, 상태 변화에 따라 너무 많은 렌더링이 발생하면서 겪었던 성능의 문제였다. 따라서 최소한의 상태를 가지고 필요한 리렌더링을 통해 성능 최적화를 이루고자 위와 같이 상태를 관리하고 있다.
# State를 관리할 때
리액트 공식문서에서는 DRY하게 상태를 관리하라고 한다. Don't Repeat Yourself 하라는 뜻인데,
# 1. state의 개수를 최소한으로 줄이기
애초에 필요하지 않는 state를 남용하지 않고 온디맨드한 state만 유지하는 것이다. 상태를 최소한으로 관리하는 것만으로도 성능을 유지할 수 있었다.
# 2. 상태가 변경되는 상황을 제어하기
다만 앱이 고도화되면 어쩔 수 없이 관리해야 할 상태가 늘어날 수밖에 없는데, 그 때에는 상태가 불필요하게 리렌더링되는 상황을 최소한으로 줄였다.
리액트의 경우 useCallback, useMemo, throttle, debounce와 같은 것들로 상태가 과다하게 변경되지 않도록 한다.
# 3. 불변성 유지하기
리액트의 state, 리덕스의 3가지 규칙에서 가장 강조하는 원칙 중 하나는 state의 불변성을 유지하는 것이다. 부수효과가 나지 않도록 상태를 변경할 때에는 기존의 상태에 직접 변화를 일으키는 것이 아닌, 새로운 상태를 만들어서 이전의 상태를 교체하는 방식을 통해야 한다.
# 2/18 CJS, AMD, UMD, ESM
모두 자바스크립트 모듈 시스템의 종류다.
# 요약
- ESM is the best module format thanks to its simple syntax, async nature, and tree-shakeability.
- UMD works everywhere and usually used as a fallback in case ESM does not work
- CJS is synchronous and good for back end.
- AMD is asynchronous and good for front end.
# CJS
CommonJS의 약자다. require로 import하는 방식.
- Node.js에서 사용하는데 서버사이드에서만 사용할 수 있고, 브라우저에서는 사용할 수 없다. CJS 방식으로 모듈 시스템을 사용하려면 웹팩이나 롤업 등 모듈 번들러를 이용해야 한다.
- 모듈을 '동기적으로' 임포트 한다.
- You can import from a library node_modules or local dir. Either by const myLocalModule = require('./some/local/file.js') or var React = require('react'); works.
- CJS로 임포트 할 때, import된 것의 복사본을 준다.
//importing
const doSomething = require('./doSomething.js');
//exporting
module.exports = function doSomething(n) {
// do something
};
# AMD (Asynchronous Module Definition)
- AMD는 모듈을 비동기적으로 임포트 한다 (hence the name).
- AMD는 프론트엔드를 위한 것이며 브라우저에서 모듈 시스템을 사용하기 위해 만들어졌다. (while CJS backend).
- AMD는 CJS보다는 덜 직관적이다. AMD는 CJS의 정반대라고 생각하면 된다.
define(['dep1', 'dep2'], function(dep1, dep2) {
//Define the module value by returning a value.
return function() {};
});
// "simplified CommonJS wrapping" https://requirejs.org/docs/whyamd.html
define(function(require) {
var dep1 = require('dep1'),
dep2 = require('dep2');
return function() {};
});
# UMD (Universal Module Definition)
- 프론트와 백에서 둘 다 동작한다.
- CJS나 AMD와는 달리, UMD는 여러 모듈 시스템을 구성할 수 있는 패턴이다. (새로운 모듈 시스템이라기보다 런타임을 확인하고 분기하는 방식)
- UMD는 주로 롤업/웹팩과 같은 번들을 사용할 때 fallback 모듈로 사용된다.
(function (root, factory) {
if (typeof define === "function" && define.amd) {
define(["jquery", "underscore"], factory);
} else if (typeof exports === "object") {
module.exports = factory(require("jquery"), require("underscore"));
} else {
root.Requester = factory(root.$, root._);
}
}(this, function ($, _) {
// this is where I defined my module implementation
var Requester = { // ... };
return Requester;
}));
# ESM
ES6부터는 언어 내에 모듈 시스템을 지원하기 시작했는데, javaScript 내부적으로 모듈을 import할 수 있게 되었다.
- 현재 최신 브라우저에서 동작한다.
- CJS의 간단한 문법과 AMD의 비동기 처리의 장점을 둘 다 취한 시스템이다.
- 트리 셰이킹이 가능하다.
- 롤업과 같은 번들러로 필요 없는 코드를 제거할 수 있고, 사이트가 더 빠르게 로드되도록 처리할 수 있다.
- HTML 안에서도 임포트할 수 있다.
import React from 'react';
<script type="module">
import { func1 } from 'my-lib';
func1();
</script>
- What the heck are CJS, AMD, UMD, and ESM in Javascript? (opens new window)
- javascript 모듈 시스템 : CJS, AMD, UMD, ESM (opens new window)
# 2/17 리액트 컴포넌트 작성할 때 고려하는 것
애플리케이션을 초기부터 설계하는 상황이 종종 있었는데, 그럴 때마다 하는 고민 no.1은 디자인 패턴, 폴더 트리와 같은 설계였다.
그 중 내가 가장 많이 차용하는 디자인 패턴이 3가지가 있는데
- 컨트롤러, 모델, 뷰를 분리하는 MVC 패턴 (opens new window),
- 단방향으로 데이터 흐름을 유지시키는 FLUX 패턴 (opens new window),
- 컴포넌트를 하나의 원자-분자-유기체로 빗대어서 설명하는 아토믹 디자인 (opens new window)이다.
1년 남짓 리액트를 공부하면서 느꼈던 것은 위의 3가지 패턴 중 하나만을 고집하여 통일성을 유지하는 것보다, 각각의 디자인 패턴을 필요한 순간에 적절하게 사용하는 것이 더 정답이었다는 것이다.
Dan Abramov가 Container와 Presentational 컴포넌트를 분리시켜서 디자인해야 한다는 의견을 냈다가 철회한 것처럼, 모든 컴포넌트 작성의 순간에 일필휘지로 써내려갈 수 있도록 도와주는 만능의 디자인 패턴은 없다는 생각..
I wrote this article a long time ago and my views have since evolved. In particular, I don’t suggest splitting your components like this anymore. If you find it natural in your codebase, this pattern can be handy. But I’ve seen it enforced without any necessity and with almost dogmatic fervor far too many times. The main reason I found it useful was because it let me separate complex stateful logic from other aspects of the component. Hooks let me do the same thing without an arbitrary division. This text is left intact for historical reasons but don’t take it too seriously. — Dan Abramov
다만 컴포넌트를 작성하면서 유의하는 3가지가 있다면,
# 1) 비즈니스와 뷰 코드의 분리
컴포넌트를 처음 작성할 때부터 SRP(Single Responsibility Principle)에 따라 하나의 컴포넌트는 최대한 핵심적인 하나의 기능을 맡도록 주의하는 편이다.
특히 비동기 로직은 필수적으로 분리하고 가능한 모듈화하려고 한다. 리액트 앱에서 거의 대부분의 상태 변화는 비동기 로직에 의한 데이터 변화로 일어나기 때문에 view에 변화를 줄 수 있는 컨트롤러 역할의 코드는 최대한 분리하여 작성해주는 편이 나중에 유지 보수하기에 수월했던 것 같다.
# 2) 재사용성
흔히 똑같은 행동을 3번 이상하면 그 때는 리팩터링이 필요한 시점이라고 말한다. 개발 비용을 줄이기 위해서 재사용이 가능하도록 공통의 컴포넌트를 만들고자 노력하는 편이다.
사실 앞에서 비즈니스와 뷰 코드를 적절히 분리하게 되면 재사용성은 자연스럽게 높아지게 되는데, 처음 작성할 때에는 직관적으로 '이렇게 작성하면 다시 쓸 수 있겠네?'하는 식으로 빠르게 작성한다. 초기 단계부터 너무 많은 재사용성을 염두해 두고 컴포넌트를 작성하면 효율이 낮아졌기 때문이다 (개발 비용 줄이려다가 역으로 얻어맞는 격). 그리고 어차피 이런 공통 컴포넌트의 경우, 개발이 더 진행될 수록 변경해야 될 사항들이 점점 눈에 들어오기 때문에 무조건 한 번은 손을 봐주어야 한다.
그럼 그 때 공통 컴포넌트를 손보면서 props를 효율적으로 고친다든지, props의 변수명과 같은 것들을 리팩터링 해주는 편이다. 또한 추가적으로 어플리케이션이 고도화 될수록 재사용이 가능한 부분을 추가로 파악해서 또 다시 재사용 가능하도록 리팩터링한다.
# 3) 성능 최적화
리액트 공식문서에 컴포넌트는 DRY해야 한다고 여러번 말한다. Don't Repeat Yourself하라는 건데 필요하지 않은 state를 남용하지 않고 온디맨드한 state만 유지하라는 것이다. 상태를 최소한으로 관리하는 것만으로도 성능을 유지할 수 있었다.
다만, 앱이 고도화되면 어쩔 수 없이 관리해야 할 상태가 많이 늘어날 수밖에 없는데..(뼈 아픈 경험 有..) 그런 상황을 대비해서 미리 useCallback, useMemo, throttle, debounce와 같은 간단한 컴포넌트 최적화는 초기 작성에서부터 해두는 편이다.
Make Work, Make Right, Make Fast. 일단 동작하게 만들고, 옳게 만들고, 빠르게 만들어라..라는 유명한 말처럼 경험 상 성능 최적화는 일단 다 만들어두고서,전체적인 컴포넌트의 관계 혹은 통합적인 시각으로 바라보아야 했다.
컴포넌트 작성에 대한 나의 의견은 여기까지다. 앞으로 1년 뒤, 3년 뒤, 10년 뒤에는 보다 발전된 나름의 패턴을 가지고 있길 바란다..👀
# 2/16 CSS 프로퍼티 선언 순서: 타입나열법
CSS 프로퍼티를 어떻게 나열할 것이냐..에 대한 설문조사 결과.
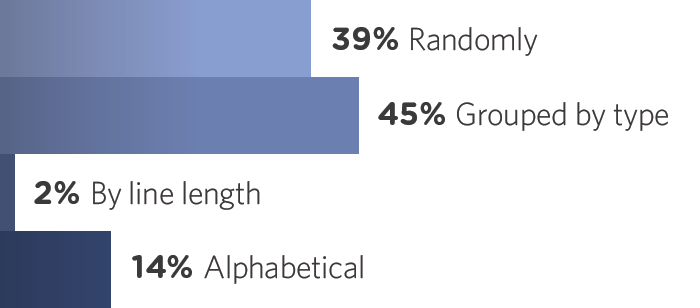
생각보다 Randomly가 많다. 나는 가능한 타입에 의한 분류를 하려고 하는 편인데, 사실 CSS 프로퍼티 나열 순서를 팀 안에서 합의를 하기가 어려울 때가 많다. (Randomly vs Grouped by type이 대치되는 상황). 그리고 스스로도 CSS 프로퍼티의 나열 순서는 리팩터링에서도 가장 후순위에 두기도 한다.
그래도 가능한 아래의 기준에 맞추어 타입 별로 나열하는 것이 장기적인 유지보수에 이롭다는 생각..!
.selector {
/* Positioning */
position: absolute;
z-index: 10;
top: 0;
right: 0;
/* Display & Box Model */
display: inline-block;
overflow: hidden;
box-sizing: border-box;
width: 100px;
height: 100px;
padding: 10px;
border: 10px solid #333;
margin: 10px;
/* Color */
background: #000;
color: #fff;
border: 1px solid black;
/* Text */
font-family: sans-serif;
font-size: 16px;
line-height: 1.4;
text-align: right;
/* Other */
cursor: pointer;
}
# references
- Poll Results: How do you order your CSS properties? (opens new window)
- 일관성있는 CSS다운 CSS를 작성하기 위한 원칙 (opens new window)
# 2/15 자바스크립트를 인터프리터 언어라고 말하면 곤란해
자바스크립트는 인터프리터 언어이긴 하다. 인터프리터 언어는 실행과 동시에 코드가 화면에 반영되는 언어를 말하는데, 개발자도구 콘솔에서 스크립트를 작성해 실행하는데 컴파일이 필요하지 않기 때문이다.
하지만 자바스크립트도 컴파일 과정을 거친다. 자바스크립트가 동작하는 대부분의 최신 브라우저의 자바스크립트 엔진에서 최적화를 위해 컴파일이 필요한 경우엔 컴파일을 하기 때문이다(JIT). 따라서 정확히 자바스크립트에서는 인터프리팅과 컴파일이 혼합되어 사용된다고 생각한다.
컴파일 언어와 인터프리터 언어의 가장 큰 차이점은 pre-processing, 컴파일 유무라는 점을 보았을 때.. 자바스크립트는 인터프리터 언어입니다!라고 자신있게 말하기엔 조금 꿉꿉한 구석이 있다는 것이다.
먼저 엔진이 실행할 JS 파일을 받게 된다. 파싱, AST(Abstract Syntax Tree)를 구축하는 과정을 거친다. 다음으로 Interpreter가 코드를 읽으며 실행한다. 코드를 수행하는 과정에서 프로파일러가 지켜보며 최적화 할 수 있는 코드를 컴파일러에게 전달해준다. 주로 반복해서 실행되는 코드 블록을 컴파일(최적화)한다.(Adaptive JITC) 그리고 원래 있던 코드와 최적화된 코드를 바꿔준다.
코드를 우선 인터프리터 방식으로 실행하고 필요할 때 컴파일 하는 방법을 JIT(Just-In-Time) 컴파일러 라고 부른다. 더 최신의 브라우저에서는 Adaptive JITC를 사용하는데, AJITC는 모든 코드를 일률적으로 같은 최적화를 적용하지 않고, 반복 수행 정도에 따라 유동적으로 adaptive하게 최적화 수준을 결정하는 방식이다.
- 컴파일러: 한 번 컴파일 하게 되면, 별도 생성된 목적 파일을 통해 빠르게 실행할 수 있다. 대용량 소스에 적합
- 인터프리터: 목적 파일 산출 과정이 없이 실행과 동시에 줄 단위로 번역이 된다. 저용량 소스에 적합
자바스크립트 생태계에서 익숙한 컴파일러를 살펴보면 Babel (opens new window)과 Typescript (opens new window)가 있다. Babel은 ES6등 최신 자바스크립트 스펙을 모든 브라우저에서 사용 가능한 스크립트로 컴파일한다. Typescript는 TS로 작성된 코드를 JS로 변환한다.
# 2/14 try-catch 에러 핸들링 주의사항
콜백으로 작성된 비동기 코드에서 try-catch 문으로 에러 처리를 하는 상황이다.
try 코드 블록 내에서 비동기 함수 setTimeout이 호출되었다고 하자. setTimeout이 호출되면 해당 함수의 실행 컨텍스트가 생성되어 콜스택에 푸시되고 실행된다. setTimeout은 비동기 함수이므로 콜백 함수가 실행되는 것을 기다리지 않고 즉시 종료되어서 콜 스택에서 제거된다. 이후 타이머가 완료되면 setTimeout의 콜백은 태스크 큐로 푸시되고 콜 스택이 비어졌을 때 이벤트 루프에 의해 콜 스택으로 푸시되어 실행된다.
setTimeout의 콜백이 실행될 때 setTimeout 함수는 이미 콜 스택에서 제거된 상태다. 이것은 setTimeout의 콜백을 실행하는 것이 setTimeout 함수가 아니라는 것을 의미한다. setTimeout 함수의 콜백 함수의 호출자가 setTimeout 함수라면 클 스택의 현재 실행 중인 실행 컨텍스트가 콜백 함수의 실행 컨텍스트일 때 현재 실행 중인 실행 컨텍스트의 하위 실행 컨텍스트가 setTimeout 함수여야 한다.
에러는 호출자 방향으로 전파된다. 즉, 콜 스택의 아래 방향(실행 중인 실행 컨텍스트가 푸시되기 직전에 푸시된 실행 컨텍스트 방향)으로 전파된다. 하지만 앞에서 살펴본 바와 같이 setTimeout 함수의 콜백을 호출한 것은 setTimeout이 아니다. 따라서 setTimeout함수의 콜백이 발생시킨 에러는 catch 블록에서 캐치되지 않는다.
function asyncTask() {
try {
setTimeout(callback, 1000); // 여기서 난 에러는
} catch (e) {
console.log(e); // 이렇게 잡을 수 없음
}
}
function asyncTask() {
setTimeout(callback, 1000); // 여기서 난 에러는
}
function callback() {
// 콜백 안에서 잡는다
try {
console.log('yes');
} catch (e) {
console.log(e);
}
}
# 2/13 Golden Circle for Coding
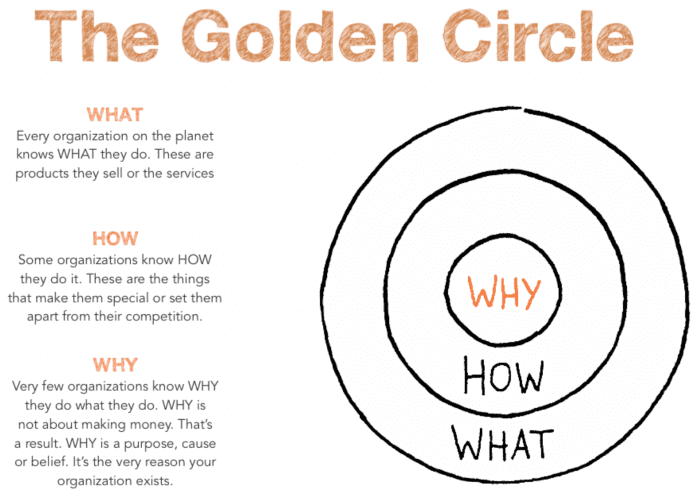
Simon Sinek의 유명한 골든 서클 이미지를 가져온 건.. 오늘 하고 싶은 이야기와 맞닿아 있기 때문..
Ted의 명강의 중에 사이먼 시넥의 강연이 있다. 훌륭한 리더들이 행동을 이끌어내는 법이라는 강연인데, 사이먼은 이 방법을 골든 서클로 설명했다.
대부분의 사람들은 보통 문제에 접근할 때 WHAT-HOW-WHY 순으로 생각하는데, 세상을 바꾸는 리더는 WHY-HOW-WHAT 순으로 접근한다. 존재 이유, 동기, 원인 이러한 것들이 명확해야 기업이 지속적으로 존속하며, 사람들의 마음을 움직이고 성공적인 결과를 이끌어낼 수 있다는 것이 골든 서클의 요지.
1년 정도 개발을 공부한 요즘엔.. 개발에도 개발의 골든 서클이 있다고 생각이 드는데..
하나의 기술을 보다 깊게 이해하기 위해서는 'WHAT'과 'HOW' 그 이전에 'WHY'에 대한 질문을 던져야 한다는 것이다. 이 기술은 왜 쓰이는 것인지, 어떤 문제를 해결하기 위해서 나온 것인지 등.. 기술의 명세보다 그 기술이 주고자 하는 가치를 생각하면 보다 깊게 이해할 수 있었다. 이것은 무엇이고 어떻게 사용하는 것인지 알기 이전에, 왜 이걸 사용해야 하는지에 대한 사유하는 걸 꾸준히 해보자.
# 2/12 시간복잡도
시간복잡도의 가장 간단한 정의는 알고리즘의 성능을 설명하는 것이다. 즉, 알고리즘을 수행하기 위해 프로세스가 수행해야 하는 연산을 수치화 한 것을 말한다.
보통 최악의 경우를 기준으로 시간복잡도를 말한다. 왜 최선의 경우를 기준으로 잡지 못할까? 최선의 경우는 어떤 알고리즘일지라도 다 만족할만한 결과를 얻기 때문에 비교 기준으로 삼을 수 없다. 그렇다면 평균적인 경우를 기준으로 잡을 순 없을까? 이는 평균적인 상황을 가정하고 정의하는 것이 어렵기 때문에 쉽지 않다. 따라서 항상 알고리즘을 평가할 때에는 최악의 상황을 염두한다.
계산법: 핵심이 되는 연산이 무엇일까?
for (let i = 0; i < n; i++) {
for (let j = 0; j < m; j++) {
for (let k = 0; k < 1000; k++) {}
}
}
// 시간복잡도는 O(n^3)인 것 같지만 O(n^2)이다
for (let i = 1; i < n; i = i * 2) {}
// 시간복잡도는 O(log n)
O(log n)이나 O(nlog n)은 현실 세계에서 이상적인 알고리즘이라고 말한다. 그리고 지수 형태의 알고리즘 O(n^2) 등은 사실상 풀 수 없는 알고리즘이라고 한다.
- 현실적 알고리즘 (P 문제): 다항시간 내에 풀 수 있는 문제 (eg. sorting, DP)
- 비현실적 알고리즘 (NP 문제): 복잡도가 팩토리얼이나 지수 형태로 올라가는 알고리즘. (eg. 해밀턴 경로문제)
# 2/11 객체지향 프로그래밍
# 객체란?
- 다른 객체와 협력하는 역할을 맡고 있는 대상
- 협력: 시스템 목표를 달성하기 위해 여러 객체가 참여하여 행동
- 역할을 맡으면 임무를 수행할 책임이 생긴다
- 책임: 협력 속에서 본인이 수행해야 할 임무의 내용을 알고 수행하는 것
- 책임을 다하기 위한 데이터와 프로세스를 갖고 있다.
- 역할: 동일한 목적을 가진 책임의 묶음
객체는 현실의 개념을 추상화한 것이다. 객체들은 서로 협력하고, 역할을 맡아 책임을 수행하여 문제상황을 해결한다. 하지만 현실의 사물과 달리 객체는 능동적이고 자율적인 존재이다.
프로토타입 기반 OOP는 클래스 기반의 OOP 와 완전히 상반되는 방식이다. 객체를 바라보는 개념 자체가 완전히 다르기 때문이다. 특히 문맥(context)을 매우 강조하는 철학을 토대로 하기 때문에 렉시컬 스코프에 의한 호이스팅과 실행 문맥에 의한 복잡한 this가 필연적으로 발생할 수밖에 없었다.
즉, 프로토타입 기반의 언어에서는 1) 현실에 존재하는 것 중 가장 좋은 본보기를 원형(프로토타입)으로 선택한다는 것. 2) 문맥(컨텍스트)에 따라 '의미'가 달라진다는 것이다.
# 프로토타입 기반 OOP 언어의 특징
- 개별 객체(instance) 수준에서 메소드와 변수를 추가
- 객체 생성은 일반적으로 복사를 통해 이루어짐
- 확장(extends)은 클래스가 아니라 위임(delegation) => 현재 객체가 메시지에 반응하지 못할 때 다른 객체로 메시지를 전달할 수 있게 하여 상속의 본질을 지원
- 개별 객체 수준에서 객체를 수정하고 발전시키는 능력은 선험적 분류의 필요성을 줄이고 반복적인 프로그래밍 및 디자인 스타일을 장려
- 프로토타입 프로그래밍은 일반적으로 분류하지 않고 유사성을 활용하도록 선택
- 결과적으로 설계는 맥락에 의해 평가
결국 프로토타입 언어에서는 분류를 우선하지 않고, 생성된 객체 위주의 유사성을 정의한다는 점. 어휘나 쓰임새는 맥락에 의해 평가 된다는 점이 중요하다.
문맥을 중요시 하기 때문에 실행 컨텍스트, 스코프 체인이 파생되었으며 클로저, 호이스팅, this와 같은 것들이 프로토타입의 '맥락'을 중요시 하는 의도를 담고 있다.
자바스크립트는 왜 프로토타입을 선택했을까 (opens new window)
# 2/10 프로세스와 스레드
- 프로그램: 어떤 작업을 위해 운영체제 위에서 실행할 수 있는 파일
- 실행단위: CPU core에서 실행하는 하나의 단위로 프로세스와 스레드를 포괄하는 개념
- 동시성: 한 순간에 여러가지 일이 아니라, 짧은 전환으로 여러가지 일을 동시에 처리하는 것처럼 보이는 것
# 프로세스와 스레드
자원은 Process 단위로 받고, 작업/스케줄링은 Thread 단위로 진행함
- 프로세스: 프로그램이 실행된 것. 프로세서에 의해 동작하고 있는 프로그램.
- 스레드 단위 작업을 지원하기 위한 자원 할당의 단위
- 프로세서: 프로세스가 동작될 수 있도록 하는 하드웨어 (= CPU)
- Stack, Heap, Data, Code로 구성
- 프로세스가 동작한다는 것은 프로세스의 특정 스레드가 실행 중이라는 뜻. 그리고 그 스레드는 프로세스가 가진 데이터를 참조함. 즉, 동작이란 프로그램의 자원들이 메모리에 올라오고, 실행되어야 할 코드의 메모리 주소를 CPU의 레지스터로 올리는 것
- 스레드: 프로세스 내에서 실행되는 작업 흐름의 단위. 한 프로세스 내에서 나뉘어진 하나 이상의 실행 단위.
- Stack을 제외한 Heap, Data, Code 영역을 하나의 프로세스 안에서 공유
# 멀티 프로세스와 멀티 스레드
CPU(프로세서)는 한순간에 하나의 프로세스만 실행할 수 있다. 한 어플리케이션에 대한 작업을 동시에 하기 위해서는 2가지 처리 방식이 있다. 동시에 실행이 되는 것처럼 보이기 위해서 실행 단위는 시분할로 CPU를 점유하며 context switching을 한다. 멀티 프로세스는 독립적인 메모리를 갖고 있지만 멀티 스레드는 자원을 공유한다.
# 멀티 프로세스
- 각 프로세스는 독립적
- IPC를 사용한 통신
- 자원 소모적, 개별 메모리 차지 -> 비효율 발생
- context switching 비용이 큼 (code, data, heap 영역의 교체가 필요)
- 동기화 작업이 필요하지 않음
# 멀티 스레드
- Thread 끼리 긴밀하게 연결되어 있음
- 공유된 자원으로 통신 비용 절감
- 공유된 자원으로 메모리가 효율적임
- context switching 비용이 적음
- 공유 자원 관리를 해야함
- 주의점
- 디버깅이 까다로움
- 한 프로세스 안의 스레드에 문제가 생기면 같은 프로세스 안의 스레드에도 같이 문제가 생김
- 같은 데이터를 공유하기 때문에 데이터 동기화에 신경 써야함
왜 멀티 스레드가 아니라 멀티 프로세스를 이용할까? (구글 크롬) 그 이유는 멀티 스레드는 서로 긴밀하게 연결되어 있기 때문에 한 스레드에 문제가 생기면 전체 프로세스에 영향이 가기 때문.
# 멀티 코어
멀티 코어는 하드웨어 측면에서 실행 단위를 병렬적으로 처리할 수 있도록 여러 프로세서가 있는 것을 말한다. 멀티 프로세스와 멀티스레드는 '처리 방식'의 일종이기 때문에 소프트웨어 쪽과 가깝고, 멀티코어는 하드웨어적 면을 말한다. 멀티코어와 관련된 키워드는 동시성과 병렬처리다.
# 동시성
하나의 코어에서 하나 이상의 프로세스(혹은 스레드)가 번갈아가면서 진행되지만 동시에 진행되는 것처럼 보이는 것
싱글코어를 가진 CPU가 실행단위를 동시에 처리하기 위해 빠른 텀으로 전환이 되면서 실행이 되는데, 이것을 동시성이라고 한다. 빠르게 번갈아가면서 실행되기 때문에 동시에 일어난 것처럼 보이게 되는 것. 짧은 순간에 CPU의 시간을 분할해서 동시에 하는 것처럼 보이게 한다.
# 병렬 처리
둘 이상의 코어에서 동시에 하나 이상의 프로세스(혹은 스레드)가 한꺼번에 진행되는 것
멀티코어는 병렬 처리, 물리적으로 여러 코어를 사용해서 다수의 실행 단위를 한순간에 처리할 수 있게 한다.
# 2/9 프론트엔드에서 Promise와 Async Function을 사용하는 이유?
프론트엔드에서 비동기 처리를 하는 이유는, 무언가를 기다려야 하는 건 유저가 아닌 브라우저의 역할이어야 하기 때문이다. 자바스크립트 개발자들은 꽤 오랫동안 비동기를 위해 콜백을 사용했다.
콜백의 가장 큰 2가지의 문제는 신뢰성(제어의 역전)과 가독성이었다.
# 신뢰성 (제어의 역전)
기존 콜백으로 처리한 비동기 코드의 문제는 외부 라이브러리에 의존하며 제어권의 주체가 바뀌게 된다는 점.
# Promise
- ES6
- 미래에 값을 반환할 수도 있는 함수를 캡슐화한 객체
- 제어의 재역전: 외부 라이브러리에 콜백 함수를 넘겨주지 않고, 비동기 요청에 대한 결과를 받아와서 직접 처리 가능. -> 신뢰성 회복
- 비동기 요청 수행에 대한 세 가지(성공, 실패, 대기)의 상태
- 내부에서 비동기 요청이 끝나고 나면 결과값을 연결된 콜백으로 보내줌
- 체이닝을 통해 구조화된 콜백 작성 가능
- 단점
- 단순 콜백 처리와 비교했을 때 성능 저하
- Promise 객체 외부에서 Promise 내의 연쇄적인 흐름에 대한 예외 처리 어려움
- 단일 값 전달의 한계: 여러 개의 값의 연관성이 부족하더라도 넘겨주려면 객체, 배열로 감싸야 함.
- Promise 함수의 내부에 들어가는 함수를 executor 함수라고 부르는데, 이 함수는 비동기 요청의 수행 결과에 따라 데이터를 넘겨줄 콜백을 인자로 받는다.
- executor 함수의 로직은 Promise 객체가 만들어지는 즉시 실행된다. (따라서 반복적인 이벤트가 발생하는 코드에서 Promise를 사용하는 것은 적절하지 않을 수도 있음)
function request() {
return new Promise(function(resolve, reject) {
ajax('url', function(data) {
if (data) {
resolve(data);
} else {
reject('Error!');
}
});
});
}
function asyncTask() {
const promise = requiest();
promise
.then(function(data) {
// data를 통한 작업 수행
})
.catch(function(error) {
// error를 이용한 예외 처리
});
}
# 가독성
비동기 !== 인간의 사고 방식 일반적으로 인간은 순차적인 사고방식에 더 친숙하지만, 비동기 코드는 동작 방식의 특성 상 직선적인 추론을 제시할 수가 없었다.
function A(callback) {
console.log('A');
setTimeout(() => callback(), 0);
}
function B() {
console.log('B');
}
function C() {
console.log('C');
}
A(B);
C(); // A -> C -> B
위의 코드에서 A -> C -> B 순서로 진행되는 비동기 처리 코드 때문에 디버깅 작업을 더욱 피로하게 만든다. 결국 비동기 코드의 단점은 인간의 사고방식과 동떨어진 비동기 자체의 특성으로 간주할 수 있다.
ES6에서 Promise의 구조화된 콜백으로 이전 콜백과 비교해 가독성은 보다 개선되었지만, 비동기 코드 자체의 가독성 문제는 해결할 수 없었다.
# Generator
위의 같은 비동기 코드의 가독성 문제를 1차적으로 해결했던 것은 Generator였다. (Async function 이전 문법에서..) Generator 함수는 비동기를 위해 나온 건 아니었지만 비동기를 동기적인 것처럼 보이게 하는 데 있어서 꽤 유용했다.
*: Generator 함수를 작성하는 규칙. function 키워드 뒤나 식별자 앞에 선언.- Iterator: generator 호출로 반환된 객체. next()를 가지고 있다.
- next(): generator 함수 안의 yield 문으로 넘어가기 위한 메서드
- yield: next()가 호출되었을 때, 1) 중간에 멈추고 2) 데이터를 받는 지점
- 함수를 도중에 중단할 수 있고 함수의 중간 지점에 값을 보낼 수 있다는 특징으로 외부의 값을 기다렸다가 받은 시점에서 함수를 실행하도록 만들 수 있음.
function* asyncTask() {
const data = yield request(); // (4) 받아온 값을 중단된 지점으로 보내서 함수를 다시 진행
// data를 이용한 작업 수행
}
function request() {
ajax('url', function(data) {
iterator.next(data); // (3) 비동기 요청을 마치고 값을 받아오면
});
}
const iterator = asyncTask(); // (1) generator 함수를 호출해 iterator 객체 반환
iterator.next(); // (2) iterator 객체의 next() 메서드를 호출하면, asyncTask의 함수의 로직을 실행하다가 첫 번째 yield문 뒤에 있는 request()를 호출하고 함수 중단
따라서 Async function이 생기기 전에 Generator와 Promise를 섞어서 비동기 코드를 작성했음. 하지만 두 문법을 혼용해서 사용하기 보다는 더 직관적인 작성을 위해 Async function 문법이 탄생.
# Async function
- ES2017
- Syntatic Sugar
- 함수 내에서 await문을 만나면 함수의 실행을 일시중지
- await 뒤에 있는 프로미스의 수행 결과 값을 받아 함수 재진행
- generator와 Promise 두 문법의 특징과 매커니즘을 이어받아 비동기 코드의 가독성을 크게 높임
- await을 통해 반환 받은 것이 Promise의 수행된 값이기 때문에 외부에서 예외처리가 용이
- 유의할 점
- Promise의 Syntatic Sugar이기 때문에 Promise에 대한 이해가 선행될 필요
- 하나의 함수 안에서 다수의 Promise를 병렬적으로 처리할 수 없음 (eg.
Promise.all,Promise.race) - async 키워드를 관련 함수마다 일일이 선언해야 할수도 있음
# 2/8 DOM이 만들어지는 과정과 주의사항
브라우저에서 HTML과 같은 리소스를 전달받으면 브라우저 엔진이 이 리소스들을 렌더링하게 된다.
HTML을 파싱하면서 encoding - pre-parsing - tokenization 하는 과정을 거쳐서 만들어지는 것이 DOM이다.
파서는 토크나이저가 만든 토큰을 DOM 객체에 삽입하는 것인데, 이때 트리 데이터 구조로 생성되기 때문에 이 프로세스를 트리 구조화라고 한다.
HTML 파싱을 어렵게하는 요인 중에서 하나를 꼽자면 파싱이 진행되는 동안 script 태그 안의 자바스크립트 코드가 또 파싱해야 할 코드를 추가하는 경우다.
자바스크립트의 DOM api 혹은 document.write()와 같은 코드가 실행되는 경우에는 HTML 파싱이 다시 실행된다는 것을 유의해야 한다.
이 파싱이 끝나면 DOMContentLoaded 이벤트가 실행되고, 웹 페이지의 모든 리소스들의 처리가 완료되면 load() 이벤트가 실행된다.
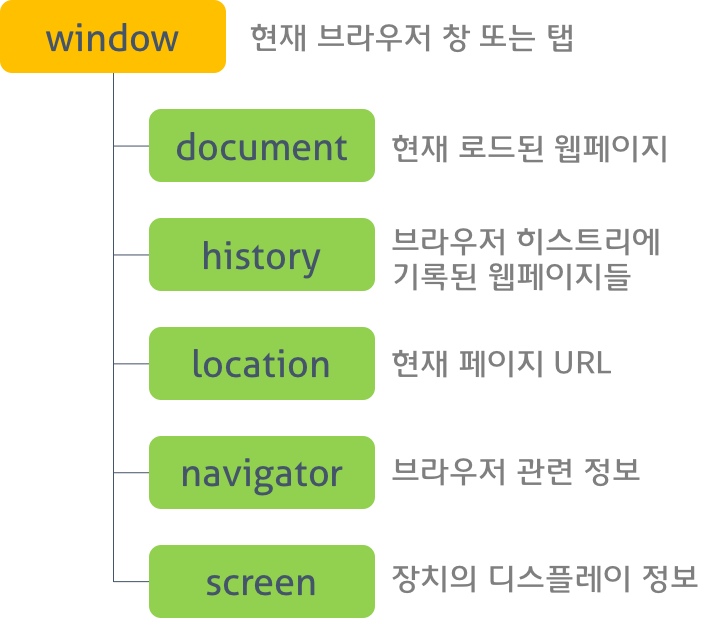
# BOM (Browser Object Model)
브라우저 객체 모델은 브라우저 탭 또는 브라우저 창의 모델을 생성한다. 최상위 객체는 window 객체로 현재 브라우저 창 또는 탭을 표현하는 객체이다. 또한 이 객체의 자식 객체 들은 브라우저의 다른 기능들을 표현한다. 이 객체들은 Standard Built-in Objects가 구성된 후에 구성된다.
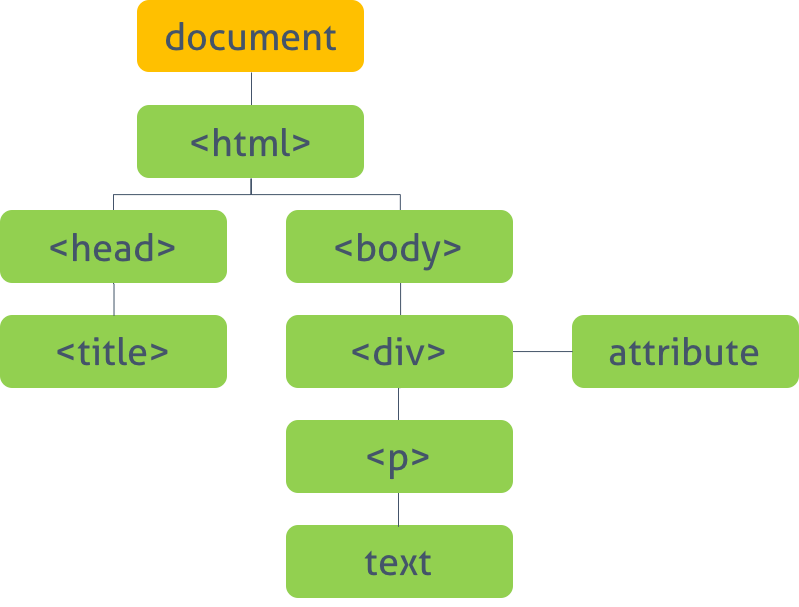
# DOM (Document Object Model)
문서 객체 모델은 현재 웹페이지의 모델을 생성한다. 최상위 객체는 document 객체로 전체 문서를 표현한다. 또한 이 객체의 자식 객체들은 문서의 다른 요소들을 표현한다. 이 객체들은 Standard Built-in Objects가 구성된 후에 구성된다.
 출처 (opens new window)
출처 (opens new window)
# 2/6 브라우저가 웹 서버로 요청을 보내는 과정
- 사용자는 주소창에
positiveko-til.vercel.app을 입력한다. - 브라우저는 해당 도메인을 HTTP 규약에 맞춰 데이터 패킷을 준비한다.
- 준비된 패킷은 랜선 혹은 AP를 통해 해당 지역의 Tier 3 ISP까지 전달된다.
- 이때 클라이언트는 빠른 응답을 위해 Cache Server에 캐싱해 놓은 결과가 있는지 먼저 확인하고, 캐시된 데이터가 있다면 더 진행하지 않고 이를 다시 클라이언트에 돌려준다.
- ISP는 DNS를 겸하기도 하기 때문에 요청으로 들어온
positiveko-til.vercel.app의 IP 주소를 호가인한다. - 만약 해당 DNS에 정보가 없다면 다른 DNS 서버에 해당 도메인이 있는지 확인한다.
positiveko-til.vercel.app의 IP 주소가76.76.21.142임을 브라우저가 알아낸다.- 브라우저는 해당 IP 주소로 HTTP Request를 보낸다.
- 해당 도메인의 WAS는 요청을 받아서 필요 시 DB 작업을 처리한다.
- 사용자 요청에 맞는 컨텐츠를 Status Code 등과 함께 HTTP Response로 돌려보낸다.
- 다시 수많은 Router와 ISP를 거쳐 사용자의 브라우저에 컨텐츠가 도달한다.
# 2/5 브라우저 처리 단계에 따른 성능 개선
페이지를 떠나는 단계에서 브라우저는 메모리 해제 작업을 실행한다. 그러나 브라우저에 따라 메모리 해제를 담당하는 가비지 컬렉션 기능이 제대로 동작하지 않아 페이지가 느려질 수 있다. 따라서 페이지 이동 단계에서 일어나는 성능 문제를 개선하기 위해서는 필요 없는 변수나 객체를 삭제하고, 이벤트를 해제해서 메모리를 관리해야 한다.
브라우저에는 여러 처리 과정이 있지만 무엇보다 네트워크 통신 단계(DNS, TCP, Request, Response)에 들어가는 비용이 가장 크다. 네트워크 통신 단계에 들어가는 비용을 줄여서 성능을 높이는 방법에는 여러가지가 있다.
- 브라우저가 허용하는 호스트 별 동시 연결 개수를 활용해서 데이터와 파일을 동시에 받는 방법
- 쿠키의 크기를 줄여 요청 헤더의 크기를 줄이기
- 스타일시트 파일과 자바스크립트 파일을 gzip으로 압축해 전송받는 파일의 크기를 줄이는 방법
- 이미 다운로드한 리소스를 캐시에 저장해서 다시 사용하는 방법
브라우저 처리 단계는 서버에서 받은 HTML과 이미지, 스타일시트를 조합해서 사용자가 실제로 보는 화면을 만드는 단계다. 이 단계에서 onload 이벤트보다 DOMContentLoaded 이벤트로 DOM을 조작하는 시점을 조절하면 웹페이지의 응답 속도를 더 빠르게 할 수 있다.
# 2/4 structuredClone()으로 깊은 복사하기
1/19 TIL (opens new window)에서 객체의 깊은 복사를 구현하는 재귀 함수를 작성했었다. 이 방법 말고는 lodash의 cloneDeep()이 만능인줄 알았더니.. structuredClone() (opens new window) 메서드가 존재했다. 아직 ECMAScript 명세에는 포함되지 않은 메서드이지만, 아래의 브라우저 환경에서 사용 가능(or 하게 될 예정)하다.
- Chrome 98
- Safari 137 (Technology Preview Release)
- Firefox 94
- Node.js 17.0
- Deno 1.14
// value와 circular reference가 있는 객체를 작성한다.
const original = { name: 'MDN' };
original.itself = original;
// clone it
const clone = structuredClone(original);
console.assert(clone !== original); // 같은 주솟값을 가지지 않으므로 다르다.
console.assert(clone.name === 'MDN'); // 같은 값을 갖는다
console.assert(clone.itself === clone); // 순환 참조는 보전된다
하지만 몇몇 빌트인 객체들은 복사하지 못한다고 한다. 여기 (opens new window)서 확인해볼 수 있다.
# 2/3 BOM, DOM

# BOM(Browser Object Model)
브라우저 객체 모델은 브라우저 탭 또는 브라우저 창의 모델을 생성한다. 최상위 객체는 window 객체로 현재 브라우저 창 또는 탭을 표현하는 객체이다.
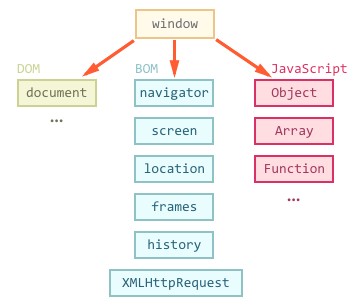
# DOM(Document Object Model)
문서 객체 모델은 현재 웹 페이지의 모델을 생성한다. 최상위 객체는 document 객체로 전체 문서를 포함한다.
# 2/2 Query Parameter & Path Variable
resource를 가져오는 GET의 경우에는 PathVariables를 사용하고, 정렬이나 필터링을 하는 경우 QueryParam을 사용
# Query Parameter
/users?id=123 // 아이디가 123인 사용자를 가져온다.
# Path Variable
/users/123; // 아이디가 123인 사용자를 가져온다.
# 각각 언제 사용할까?
만약 어떤 resource를 식별하고 싶으면 PathVariable을 사용하고, 정렬이나 필터링을 한다면 Query Parameter를 사용하는 것이 좋음.
# 2/1 빌트인 객체, 호스트 객체
# 표준 빌트인 객체
- ECMAScript 사양에 정의된 객체이며 애플리케이션 전역의 공통적인 기능을 제공
- 자바스크립트 실행 환경과 관계 없이 언제나 사용 가능
- 별도의 선언 없이 전역 변수처럼 언제나 참조 가능
# 호스트 객체
- ECMAScript 사양에 정의되어 있지 않지만 자바스크립트 실행 환경에서 추가로 제공하는 객체
- 브라우저에서는 클라이언트 사이드 Web API(DOM, fetch, Canvas, SVG, Web Storage, Web Worker 등)를 호스트 객체로 제공
- Node.js 환경에서는 Node.js 고유의 API를 호스트로 제공
# 사용자 정의 객체
- 표준 빌트인 객체나 호스트 객체처럼 기본 제공되는 객체가 아닌 사용자가 직접 정의한 객체